Data governance for generative AI explained in simple steps. Learn ingestion, vector management, privacy controls, and best practices to build safe and compliant AI systems.




In the case of Generative AI, breaking the data governance process into clear steps makes it easier to follow and understand. Governing vector embeddings might sound hard.
The reality is that it is built on logical stages.
How hard data governance in generative AI is aside, the market is expected to grow to at least 15 billion USD by 2034!
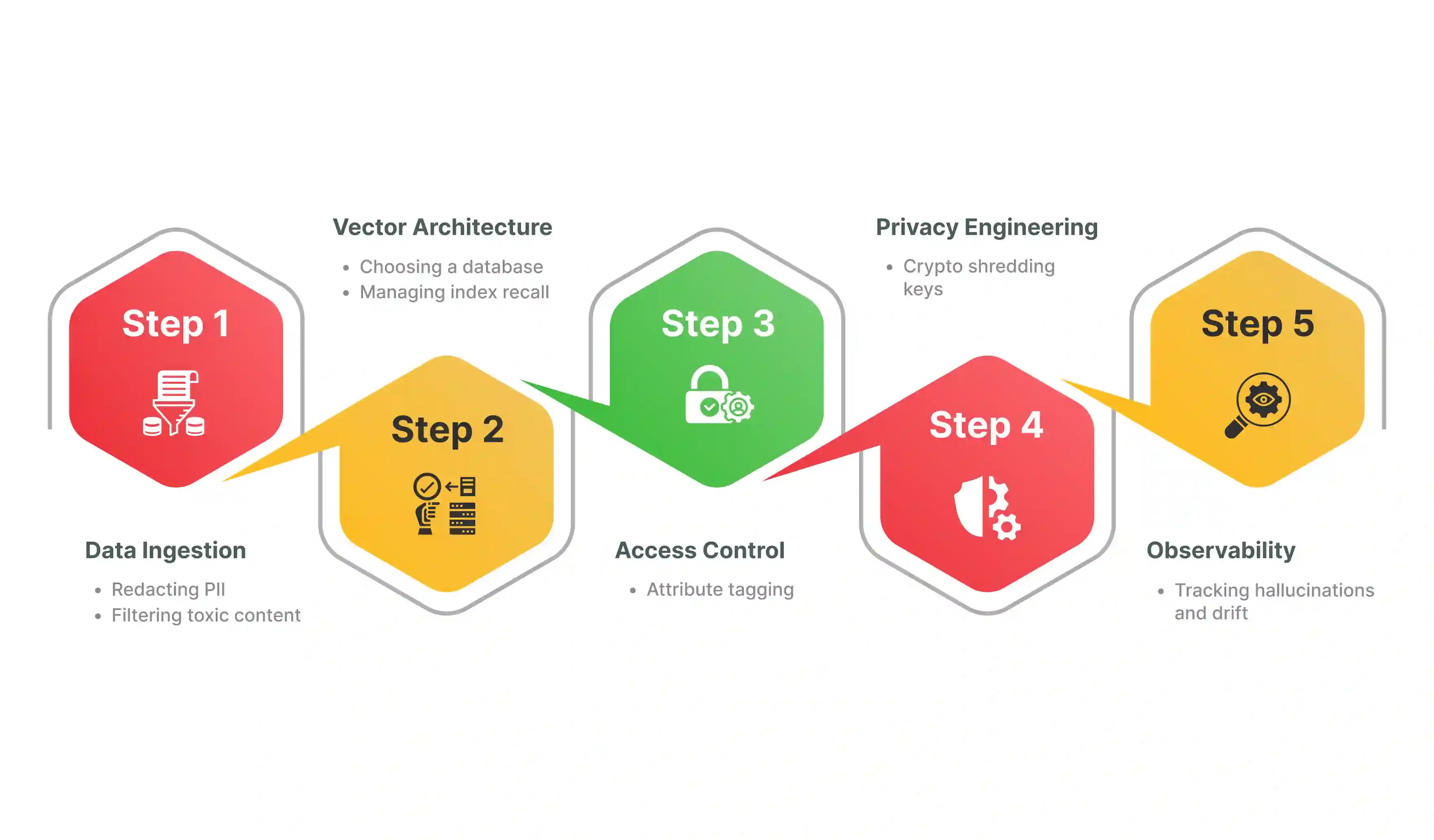
This means getting familiar with data governance as early as possible can be a smart move that pays off. Here is how the process works:
The first step in understanding the data governance in the generative AI process is controlling what enters the system.
This step is important for developing accurate models. This part of the process involves gathering diverse and relevant datasets from unstructured sources. It allows coverage of major variables.
In this step, companies use techniques like automated sanitization pipelines. These tools remove sensitive data before it turns into a vector. This keeps the vector database clean. It also stops the model from learning things it should not know.
While there are several stages in the generative AI data governance process, one major aspect of architecture is its focus on choosing the right storage engine. This involves picking between specialized vector databases or adding vector tools to current SQL databases.
Additionally, techniques like physical sharding separate data for different users. This measure for data governance in generative AI lowers the risk of leaks. With methods such as index optimization and version management, companies verify that the system runs fast and stays safe.
Setting up permissions involves teaching the system who can see what data. This step in the generative AI data governance process uses attributes and metadata tags to help the system filter results. It is where the real work begins in security.
Privacy engineering checks how well the system handles data deletion. This step in generative AI data governance is like a safety net. This step in data governance for generative AI makes sure that the system is ready for user requests to delete their info. It helps uncover gaps in compliance before a real audit happens.
Observability is the final step in the governance process. Here, the system for generative AI data governance moves from testing to real-world use. It starts checking outputs for errors or lies. This step in data governance for generative AI connects the model to monitors that track its health.

Pinecone is often used for massive datasets. This type of tool works best when the team needs a managed service. To get good results with generative AI data governance companies use this platform to offload work.
However, it is a closed-source tool. This means moving data out later can be hard. Companies that need to move fast often choose this option. It takes care of the backend work so teams can work on the app.
The Weaviate database is great for projects that need strong separation between users. What this model does is use physical sharding.
For this, choosing the right setup for each tenant is key to success in your process. Tech teams use this to keep full control over how data is stored. This database for generative AI data governance also lets them mix keyword search with vector search for better answers.
Milvus is widely used for systems that need to grow very large. This works well when you need to separate storage from computing power.
Checking for bottlenecks helps improve speed in your generative AI data governance model. It allows for scaling one part of the system without changing the other. This saves money and keeps the system running smoothly.
Qdrant is a fast engine that handles both search and filtering well. This type of tool in your process works well when you need to filter data by many tags.
This makes sure the data matches the query rules and improves results. Developers like it because it is written in a fast language called Rust. It gives good speed for the cost.
PostgreSQL is used to add vector search to a standard database. It is perfect for teams that want to keep their current setup.
This keeps data in one place and lowers security risks. Teams use this when they want to use proven security tools they already have. It helps them follow strict data laws without buying new tools.
Elasticsearch is helpful for companies that already use it for logs. This can be useful in your generative AI data governance process when you want to join text search with vectors.
While using Elasticsearch, you need to make sure your hardware can handle the load. Large firms use this to keep their tech stack simple. It stops them from having too many different databases to manage.
Crypto shredding is used to delete data in a secure way. It works by encrypting each user record with a unique key.
When a user asks to be forgotten, the system deletes the key. This makes the data unreadable forever. This concept in generative AI data governance is the best way to handle privacy laws in vector databases.
This method controls access by looking at tags on the data. It is commonly used to stop users from seeing sensitive files.
When using this method, make sure to filter the query before searching. This concept in generative AI data governance stops the system from wasting time on files the user cannot see. It keeps the system fast and safe.
Observability tracks how well the model behaves. It is best for processes where you need to trust the output.
When applying this check for signs that the model is hallucinating. This is how companies stop the generative AI data governance model from giving bad advice. It alerts the team when things go wrong.
Versioning keeps track of changes to the vector model. It works well when models get updated often.
When using versioning, pay attention to which index goes with which model. This stops the generative AI data governance system from breaking when a new update comes out.
Sharding divides the database into physical pieces for each user. It is best for scenarios where data must never mix.
To get the best results, give each large client their own shard. This stops data from leaking between users. It is a strict way to manage multi-tenant systems.
Sanitization cleans text before it enters the database. This can be useful in generative AI data governance when sources contain private info.
How so? Well, while using sanitization, consider stripping out hidden metadata. This kind of cleaning prevents attacks where bad actors hide commands in text files.
Entrans has worked with 50+ companies, including Fortune 500 companies, and is equipped to handle security design and data engineering from the ground up.
Want to use AI but are working with legacy systems?
Well, we modernize and migrate them to the platform you want! If you don’t want to change the full system?
Then why not add agentic AI on top of your existing framework for better automation and to run modern frameworks!
This way, you can make sure that your data governance for generative AI processes stays ahead and is updated in real time.
From privacy engineering to testing and even full-stack work, we can handle projects using industry experts and under NDA for full privacy.
Want to know more? Why not reach out for a free consultation call?
Physical sharding improves the security of the storage process. By putting each user on a separate storage block these barriers stop data from leaking to other users. This not only keeps data safe but also meets strict laws that demand clear separation of client info.
The testing step in a typical Data Governance for Generative AI process involves using the keys to check if data is truly gone. During this phase the team tries to read the data after deleting the key to get a true check of the privacy system.
The primary function of the pre-filtering process is to apply rules before the search happens. After a user sends a query the system filters out blocked files first. This stops the search from looking at data the user has no right to see.
Postgres simplifies data governance for generative AI processes by letting teams use tools they know. It offers a set of features for every stage of the data life cycle from locking rows to logging actions. This allows security teams to focus on setting rules rather than learning new tools.
Steps in the governance process typically include ingestion, where clean data is gathered, followed by architecture, which involves choosing the right database. Next is access control, where tags are used to filter views and then privacy engineering, where deletion keys are managed. The final step is observability.
Observability plays a major role in the safety process of AI agents by allowing teams to spot errors and fix them fast without stopping the system. By checking logs and scores tools can find bad outputs and stop the agent from acting on them.
With data governance for generative AI, the process data is typically split by the model version used to create it. A common way is to make a new index for every new model update. The old index is kept until the new one is tested and proven to work.
The first step in the generative AI data governance process is data ingestion. This involves cleaning incoming text from various sources that will be used to create vectors. The quality of the cleaning affects the safety and truth of the answers.
Data governance for generative AI for finance firms often centers on tasks like fraud checks and keeping data private. By analyzing logs models can find odd patterns that may point to bad actors helping to stop money loss. Also these models are used to check risk for loans.
In healthcare data governance for generative AI is used to protect patient files and improve care quality. By checking data access logs models can spot when someone looks at a file they should not see allowing for security to step in. These models also help in finding patterns in patient history to predict needs.